
近日,我院2023级硕士研究生王澳在人工智能安全领域取得重要进展,研究论文《Enhancing the Transferability of Jailbreak Attacks on Large Language Models via Exploiting Reparameterization Invariance》被自然语言处理领域国际顶级会议ACL 2026主会收录,通讯作者为刘伟锋教授,指导老师为杨兴浩副教授,太阳集团tyc234cc为第一署名单位和通讯单位。
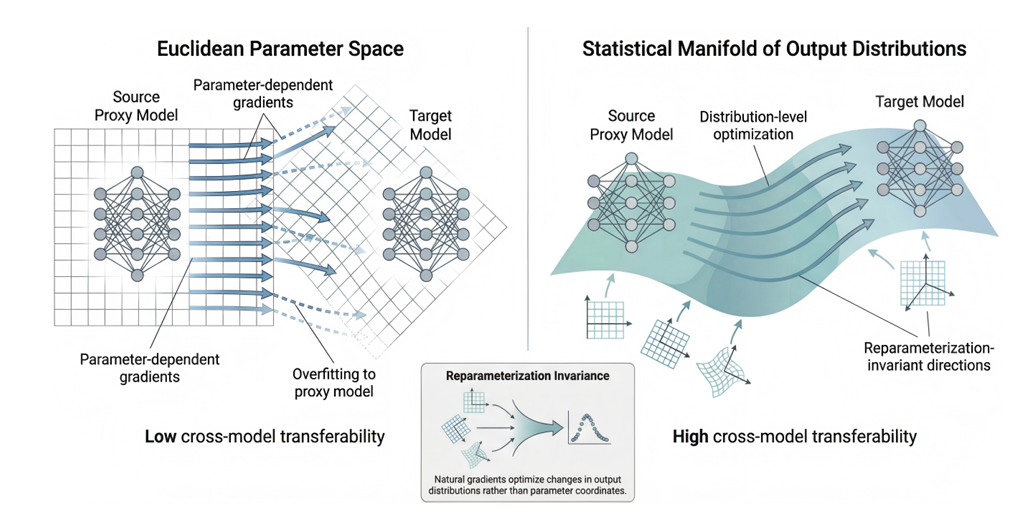
该工作聚焦于大模型安全对齐机制中的关键挑战——越狱攻击的跨模型迁移性问题。文章指出尽管现有基于梯度的token级攻击在开源模型上表现出较高成功率,但其优化过程依赖特定模型的参数空间,导致在单一代理模型上生成的越狱样本难以泛化至其他目标模型。研究发现,这一局限性本质上源于传统方法基于欧氏空间的优化路径,其梯度方向与模型参数化形式强相关,难以捕捉不同模型之间共享的攻击脆弱性。为此,本文从信息几何视角出发,提出了基于重参数化不变性的越狱攻击框架(RIGJ)。该方法利用自然梯度在输出分布流形上的优化特性,以KL散度度量扰动对模型输出分布的影响,从而构建与具体模型参数无关的优化方向,实现跨模型一致的攻击轨迹。具体来说,本文设计了对角Fisher信息矩阵近似以提升计算效率,并结合Gumbel-Softmax松弛机制缓解连续优化与离散token之间的不匹配问题,同时引入基于语义空间的样本锚定目标,有效提升攻击的稳定性与泛化能力。此外,通过多样本联合优化与前缀攻击策略,进一步增强了攻击效果与实际适用性。实验结果表明,该方法在多个主流开源与闭源大模型上均取得显著优势,相比现有最优方法,在跨模型攻击成功率与有害性评分上分别提升14.9%和1.23,同时在计算效率与对抗防御鲁棒性方面也表现出更优性能。相关研究为理解大语言模型安全对齐机制中的结构性弱点提供了新的理论视角,并为构建更加鲁棒的安全防御策略奠定了基础。
ACL是自然语言处理领域最具影响力的国际学术会议之一,与EMNLP、NAACL共同构成该领域的顶级学术会议体系,是中国计算机学会(CCF)推荐的A类国际会议。ACL 2026主会论文录用率约为19%,体现了会议严格的评审标准与高水平的学术影响力。
刘伟锋教授团队研究方向主要为机器学习、人工智能、智能信息处理算法等。现有教授1人,副教授3人,讲师4人。团队的青年人才培养工作近两年取得很大进展,2022年至今团队青年教师已经获得国家自然基金青年基金4项,山东省国家海外青年人才项目1项,山东省泰山学者青年专家1项等多个国家和省级项目。此外,团队青年教师已经多次在IEEE TPAMI、IEEE TIP、IEEE TKDE、ICML、ICLR、CVPR、AAAI、ACL、EMNLP、IJCAI等人工智能顶级期刊和会议发表相关研究工作,受到领域的广泛关注。


 实验教学平台
实验教学平台 学校OA系统
学校OA系统 学校邮件系统
学校邮件系统 相关文件查询
相关文件查询